Make tiny progress every day. ——yangnanbei
参考资料:
- https://perf.wiki.kernel.org
- man手册
- https://www.youtube.com/playlist?list=PLx-WakpEO8zFQGRrB4xYAuWjHKqVWlwaD
- Perf更详细的介绍 – 陈小欧 – 20210512 – PLCT实验室_哔哩哔哩_bilibili
- https://zhuanlan.zhihu.com/p/147875569
前言
还记得我第一份工作刚入职开发的第一个接口,在网络栈入口加了一个对事件A的处理。那时候虚线的+1强调要注意这一块的性能,还反复修改了几次。那时我问为什么?他只说这是处理链路必经的流程,所以性能要着重考虑。
实际上,由“必经链路”推出“性能处理重要”难免有局部过度优化的嫌疑。性能问题也遵循20/80原则,即80%的性能问题是由20%的性能不友好代码造成的,如何定位性能不友好的代码是性能分析中很重要的课题。
perf工具正是我们定位性能问题的好帮手,perf 是 Linux 系统性能分析和优化的基石工具。它最大的价值在于提供了一个高效、低开销、深度集成的途径,让开发者能够跨越硬件、内核、用户应用的界限,精确地定位性能瓶颈的根源(精确到函数、源码行甚至指令)。无论是进行微观的代码优化,还是诊断宏观的系统级问题,perf 都是不可或缺的利器。掌握 perf 是 Linux 开发者和性能工程师的核心技能之一。
让我们请大D老师介绍一下perf吧:
使用 perf 的背景/原因:
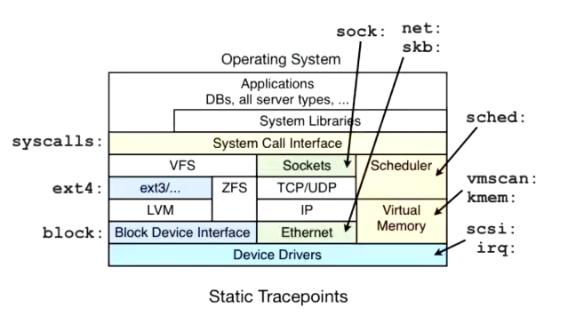
- 内核集成: 作为内核的一部分(通过
perf_event_open系统调用),perf具有极高的权限和低开销,能访问底层硬件计数器和内核内部状态。 - 替代传统工具: 它整合并超越了之前分散的工具如
oprofile、ptrace的部分功能,提供了更统一、高效的界面。 - 硬件支持: 直接利用 CPU(Intel 的 PMU, AMD 的 IBS, ARM 的 PMU 等)提供的硬件性能计数器,精确测量如 CPU 周期、指令数、缓存命中/失效、分支预测错误等底层硬件事件。
- 软件抽象: 除了硬件事件,还能访问软件事件(如页面错误、上下文切换、调度事件)和跟踪点(内核中预定义的静态探测点)以及动态探针(kprobes, uprobes)。
- 解决性能痛点: 在复杂的现代系统(多核、超线程、NUMA、复杂软件栈)中定位性能瓶颈(CPU、内存、I/O、锁争用等)非常困难,需要深入且全面的工具。
使用 perf 的主要好处:
- 功能全面(One Tool to Rule Them All):
- CPU 分析: 分析热点函数、指令级开销、CPI 等。
- 缓存分析: 定位缓存未命中(L1/L2/L3 dTLB/iTLB)的代码位置。
- 内存分析: 分析内存访问模式、带宽、缺页异常。
- I/O 分析: 跟踪块设备 I/O、同步开销(虽然不如
bpftrace/eBPF灵活,但基础支持)。 - 调度分析: 分析上下文切换、CPU 迁移、负载均衡问题、调度延迟。
- 锁分析: 检测锁争用、自旋锁持有时间。
- 调用链分析: 记录并可视化函数调用关系(stack traces)。
- 跟踪: 记录内核和用户空间特定事件的发生序列(
perf record -e tracepoint)。 - 静态/动态探针: 在函数入口/出口或任意指令处插入探测点收集数据。
- 低开销:
- 利用硬件计数器进行采样,开销通常很低(尤其是采样模式),适合生产环境使用。
- 内核级实现避免了频繁的用户/内核态切换。
- 深度洞察(从硬件到应用):
- 跨越层级: 能将硬件事件(如缓存未命中)直接关联到特定的内核函数甚至用户空间的代码行或指令。这是其最强大的优势之一。
- 精确到指令/源码行: 结合调试信息(
-g),可以将性能事件定位到源代码行或汇编指令。
- 生产环境友好:
- 低开销使其能够在真实负载下运行,捕获实际生产环境中的问题,而不仅仅是在测试环境中。
- 不需要修改或重启应用程序。
- 丰富的报告和可视化:
perf report: 交互式查看采样结果,按函数、源码行、指令排序热点。perf annotate: 将汇编指令或源码行与事件计数关联显示。perf script: 导出原始数据供自定义脚本分析(如生成火焰图)。- 火焰图:
perf数据是生成 CPU、内存火焰图(FlameGraph)的标准输入来源,提供直观的性能瓶颈可视化。
- 强大的统计功能:
perf stat: 快速运行一个命令并汇总整个执行过程中的各种硬件/软件事件计数,提供宏观性能指标(如 IPC – Instructions Per Cycle)。
- 活跃的社区和生态系统:
- 作为 Linux 内核的一部分,持续更新,支持新硬件和新特性。
- 有大量的教程、博客文章、案例分析和工具(如火焰图生成脚本)围绕它展开。
- 相对易用性(相比更底层的工具):
- 提供了相对高级的命令行接口,抽象了底层硬件的复杂性。
- 常用场景(如 CPU 热点分析)的命令(
perf record,perf report)学习曲线相对平缓。
命令
主包在wsl环境实验,部分硬件计数无法采集。
perf list
显示当下环境perf支持的trace point
perf list
List of pre-defined events (to be used in -e or -M):
alignment-faults [Software event]
bpf-output [Software event]
cgroup-switches [Software event]
context-switches OR cs [Software event]
cpu-clock [Software event]
cpu-migrations OR migrations [Software event]
dummy [Software event]
emulation-faults [Software event]
major-faults [Software event]
minor-faults [Software event]
page-faults OR faults [Software event]
task-clock [Software event]
tool:
duration_time
user_time
system_time
msr/pperf/ [Kernel PMU event]
msr/smi/ [Kernel PMU event]
msr/tsc/ [Kernel PMU event]
rNNN [Raw hardware event descriptor]
...统计分类
perf list | awk -F: ‘/Tracepoint event/ { lib[$1]++ } END {
for (l in lib) {printf ” %-16.16s %d\n”, l, lib[l] } } ‘ | sort | column
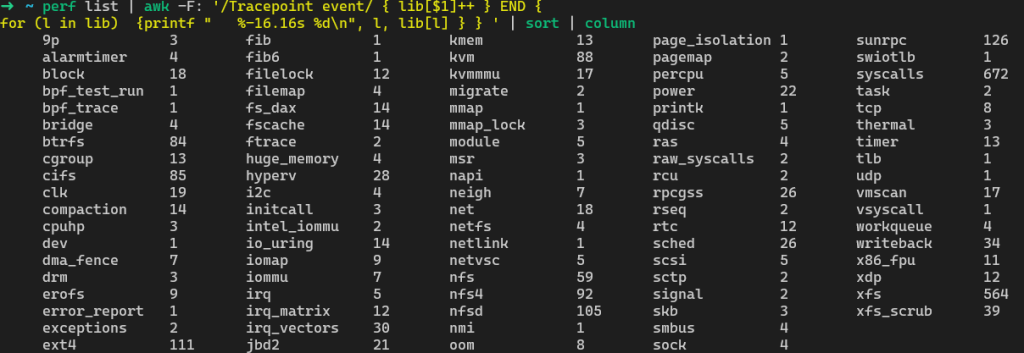
- Syscalls: syscall enter and exit
- Ext4: file system events
- Block: block device event
- Sock: socket event
- Sched: cpu schedule
- Kmem: kernel memery event
perf stat
统计事件计数
perf stat -h
usage: perf stat [<options>] [<command>]
-e, --event <event> event selector. use 'perf list' to list available events
-i, --no-inherit child tasks do not inherit counters
-p, --pid <n> stat events on existing process id
-t, --tid <n> stat events on existing thread id
-a, --all-cpus system-wide collection from all CPUs
-c, --scale scale/normalize counters
-v, --verbose be more verbose (show counter open errors, etc)
-r, --repeat <n> repeat command and print average + stddev (max: 100)
-n, --null null run - dont start any counters
-B, --big-num print large numbers with thousands' separators我们可以选择想要统计的事件类型
perf stat -e cycles dd if=/dev/zero of=/dev/null count=100000
- 默认统计用户态和内核态
perf stat -e cycles:u dd if=/dev/zero of=/dev/null count=100000
- 只统计用户态
perf stat -e cycles:uk dd if=/dev/zero of=/dev/null count=100000
- 显示指定统计 用户态+内核态
每1s统计一次
perf stat -a -I 1000 — sleep 3
- -I 1000:每1000ms统计一次
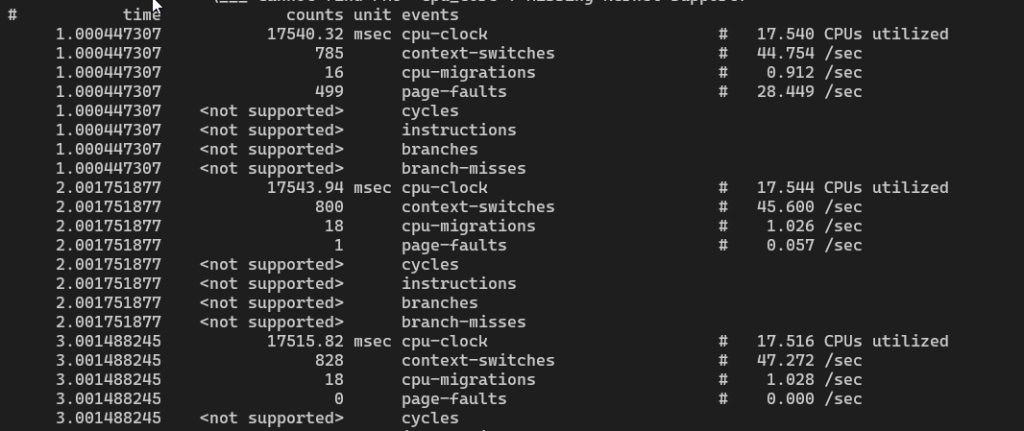
统计特定事件
perf stat -e cycles,instructions,cache-misses […]
我们可以统计某个事件,或者特定事件
可以重复运行多次
perf stat -e cache-misses -r 5 sleep 1
可以用通配符匹配特定事件
perf stat -e ‘syscalls:sys_enter_*’ -C 1 — sleep 1
匹配后过滤 次数不为0的事件
perf stat -e ‘syscalls:sys_enter_*’ -C 1 — sleep 1 2>&1 | awk ‘$1 != 0’
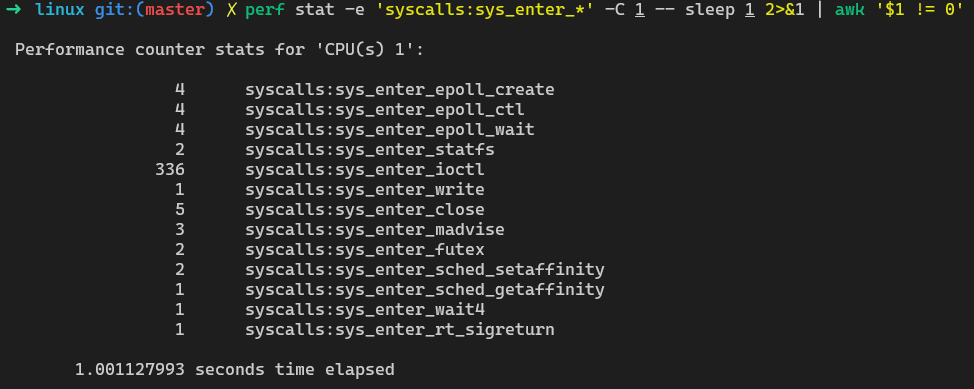
统计特定核
高性能进程的数据面线程往往是绑定且独占特定的cpu核,我们可以统计某个/某些核的特定事件技术
如:
perf stat -B -e cycles:u,instructions:u -a -C 0,2-3 sleep 5
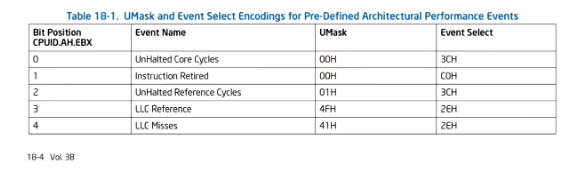
PMU raw counter
还可以统计一些CPU性能监控(PMU, Performance Monitoring Unit)事件
perf stat -e r003c -a sleep 1
如 003C: UnHalted Core Cycles
perf trace
跟踪事件
跟踪某个核上的锁事件
perf trace -e futex -C 2
perf record
采样事件以供分析
对于事件可分析的数据比起stat更详细,可以跟踪堆栈
perf record -e block:block_rq_complete -a sleep 2
perf script
展示record的信息
如
perf record -e block:block_rq_complete -a sleep 2
采样结束后使用perf script
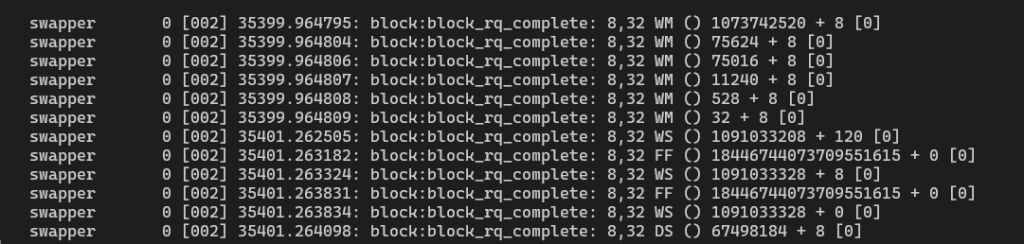
以上每列分别代表
command, pid, cpuid, timestamp, event name, storage device major and minor number, type of I/O, block command details, storage device offset + sizeof I/O, errors.
以上是通过经验对照得来的,我们可以使用-F参数来指定想要display的列(man perf-script)。
-F, –fields
Comma separated list of fields to print. Options are: comm, tid, pid, time, cpu, event, trace, ip, sym,
dso, dsoff, addr, symoff, srcline, period, iregs, uregs, brstack, brstacksym, flags, bpf-output,
brstackinsn, brstackinsnlen, brstackoff, callindent, insn, insnlen, synth, phys_addr, metric, misc,
srccode, ipc, data_page_size, code_page_size, ins_lat, machine_pid, vcpu, cgroup, retire_lat. Field list
can be prepended with the type, trace, sw or hw, to indicate to which event type the field list applies.
e.g., -F sw:comm,tid,time,ip,sym and -F trace:time,cpu,trace
perf top
实时动态跟踪事件
perf report
整理报告,将记录的报告整理成进程,事件,堆栈等
perf bench
跑测试
perf lock
跟踪锁事件
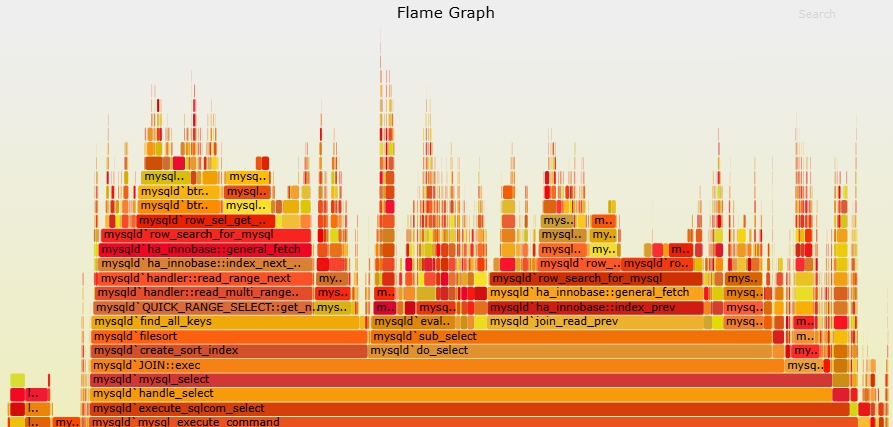
Flame Graph
我们可以将perf record记录的数据以火焰图的形式输出,更加的直观,有利于人类的阅读
https://zhuanlan.zhihu.com/p/147875569
火焰图工作调优性能做报告时经常使用,在此不多赘述了
perf record -a -g -F 99 sleep 60
perf script report flamegraph
google-chrome flamegraph.html实验
环境搭建
由于我在宿舍使用的是WSL ubutnu版本,其对微软魔改内核支持的不够好,按照系统的提示不能成功。此问题可以通过手动编译、换发行版、安装其他软件包的方式解决。
手动编译perf
本方法参考自:Install perf on WSL 2 · GitHub
依次运行如下指令
apt install flex bison
git clone https://github.com/microsoft/WSL2-Linux-Kernel --depth 1
cd WSL2-Linux-Kernel/tools/perf
make -j8
sudo cp perf /usr/local/bin装了一堆依赖~
但是查看perf list发现,由于WSL2的虚拟化兼容硬件不好,不支持部分硬件采样,如branch-miss,先这样吧。
perf script安装(for flame graph)
https://askubuntu.com/questions/1397419/how-can-i-get-pre-canned-scripts-for-perf-script






你好